
Durante mi presentación de Git Intermedio en LinuxCabal recibí una pregunta que, aunque en su momento contesté, no pude ser convincente. La pregunta: ¿por qué y cuándo usar Rebase en lugar de Merge, especialmente considerando que Merge es un proceso más transparente?
Siento que en ese momento me fui con una finta: al plantear la pregunta de esa manera se implica que Merge y Rebase son dos operaciones diferentes que sirven para lograr el mismo objetivo. Este concepto es equivocado. Contestar la pregunta sin corregirla sólo nos va a llevar a respuestas incorrectas y confusas. La realidad es que Merge y Rebase son operaciones distintas y con diferente propósito pero tienen similitudes que las hacen parecer operaciones similares.
Explico primero lo que es cada uno. Es importante mantener en mente que en Git los commits son estados del contenido (snapshots). Git almacena contenido, no diferencias ni parches.
Qué es Git Merge
El propósito de Merge es que múltiples ramas apunten a un mismo commit que mantenga el contenido de todas las ramas involucradas, mezcladas. Esto Git lo logra con lo que se conoce como commit de mezcla o merge commit. Esto significa que Merge manipula múltiples ramas. Sin embargo, hay un caso especial en el que se puede utilizar otra técnica llamada avance rápido o fast-forward. Esta técnica no necesita un commit de mezcla. Comprendamos ambos casos.
Commit de mezcla (merge commit)
Cuando las ramas han divergido, es decir, que una no es ancestra de otra, Git puede lograr el Merge haciendo un nuevo commit adicional que tenga múltiples padres. Si se tiene un commit A y un commit B en ramas diferentes y mezclas las ramas (haces el Merge) el resultado es un commit C cuyos padres son A y B. ¿Recuerdas lo que decía de que Git no almacena cambios sino snapshots del contenido? Git intentará crear un contenido C que corresponda a la mezcla de A y B por medio de diferentes técnicas. Si Git no lo logra, esto resultará en un conflicto que deberá ser resuelto manualmente. Al resolver el conflicto estarás, efectivamente, editando el snapshot que se almacenará como commit C. Una vez hecho esto, si se usa git show C (que nos da las diferencias de C con rspecto de sus dos commits anteriores, A y B), Git calcula las diferencias en el momento. Esas diferencias nunca fueron almacenadas, sólo el resultado de la mezcla.
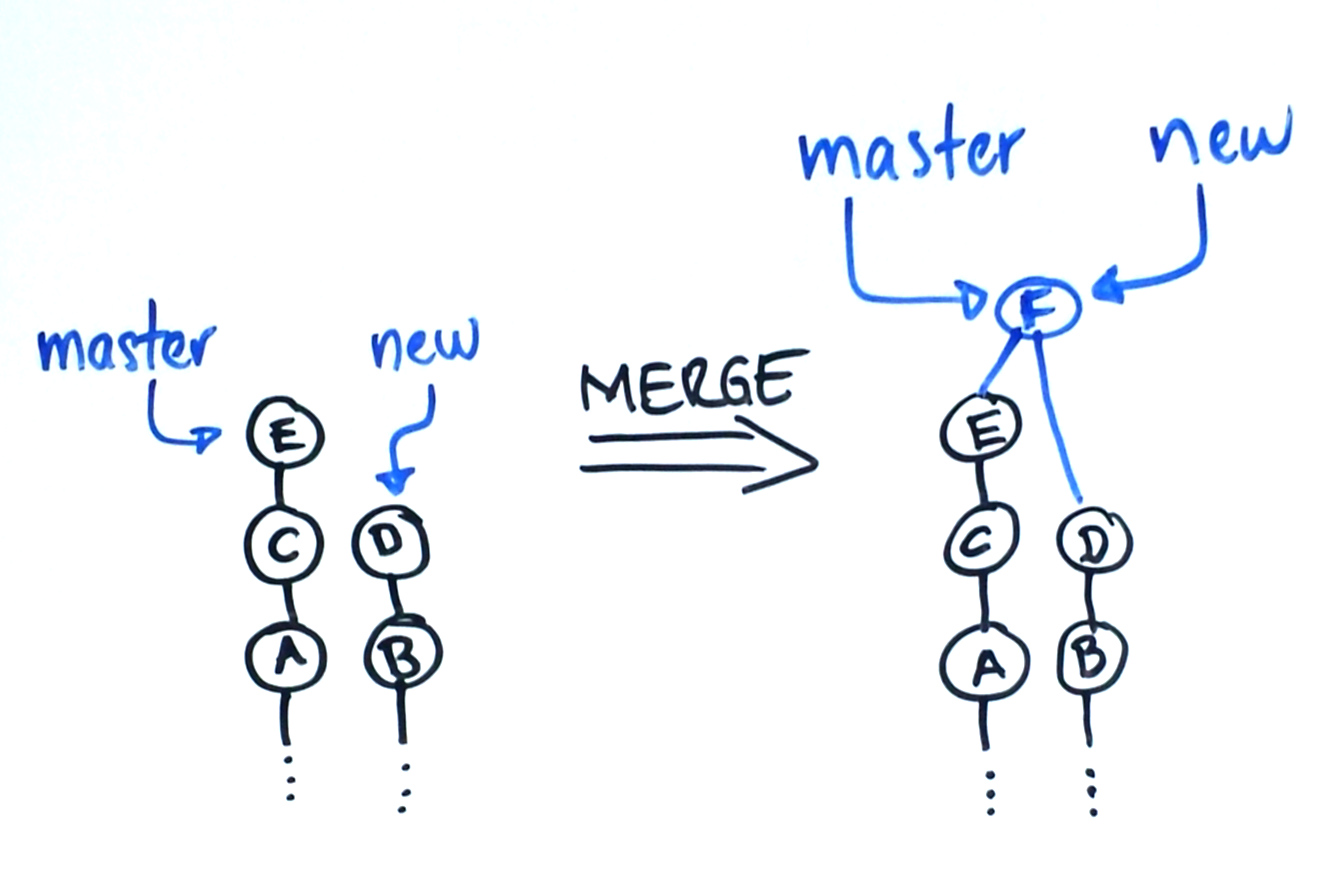
Avance rápido (fast-forward)
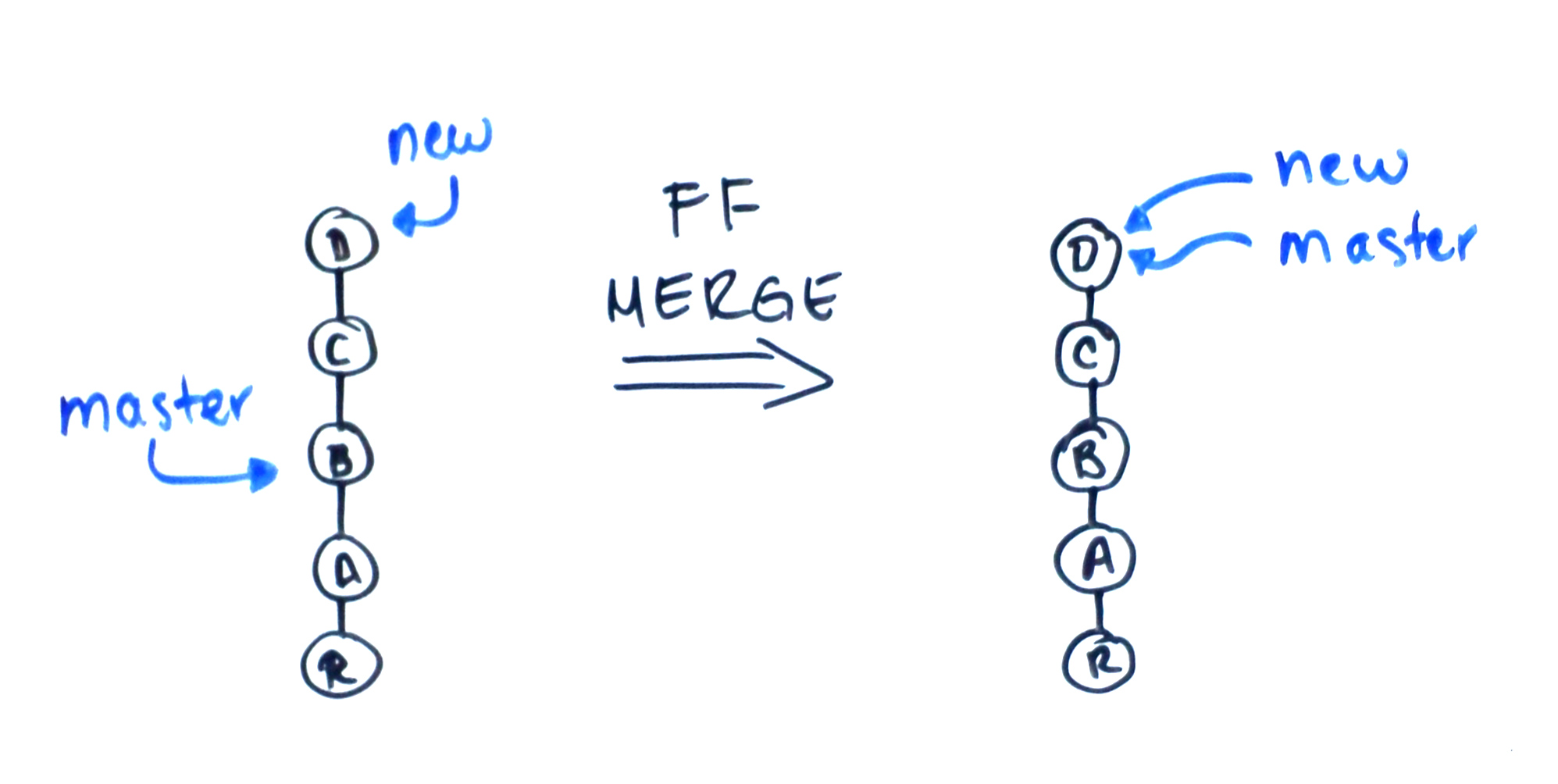
Decía que hay un caso especial de Merge: si las ramas a mezclar son directamente ancestros una de otra, entonces Git puede concluir que la rama más reciente ya incluye el contenido de la rama más antigua. En este caso, en lugar de hacer el commit de mezcla, Git sólo hace lo que se conoce como un fast-forward: sólo reapuntar la rama más vieja a la rama más nueva.
En este caso, parece ser que Git manipuló sólo una rama, pero en realidad lo hizo como una mera optimización porque hacerlo por medio de un commit de mezcla desperdiciaría un commit. De hecho, sí es posible hacerlo, y es por medio de git merge --no-ff.
Qué es Git Rebase
Por el contrario, Rebase no busca unificar ramas en un solo commit; su propósito es reaplicar un historial de cambios. Por naturaleza, manipula sólo una rama. Puede ser interactivo o no.
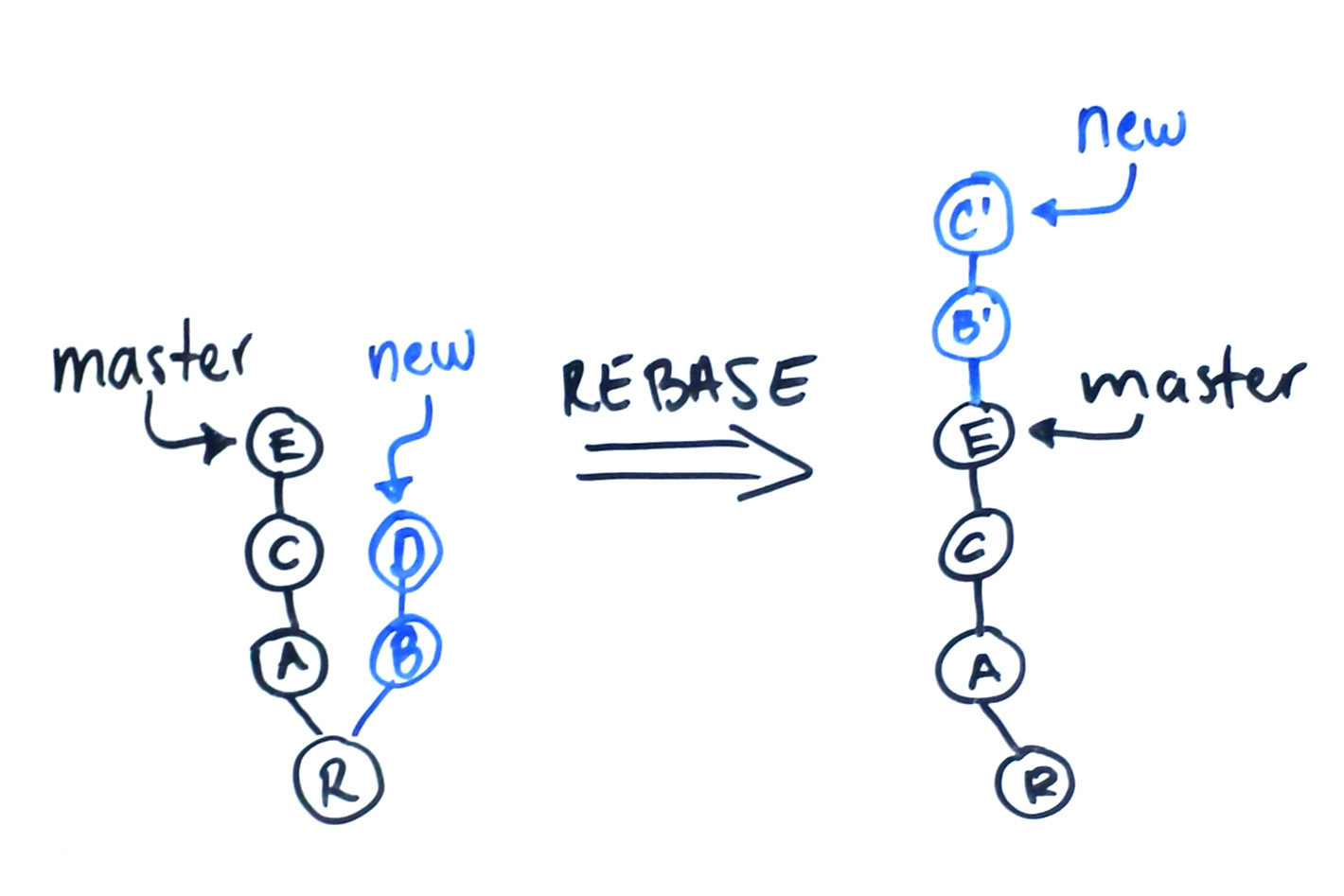
Si tengo mi rama «master» con una serie de commits A, B y C (siendo C el más reciente) y tengo una rama «nueva» con un commit V que parte del commit A, entonces puedo reaplicar V sobre C, quedando «master» desde C y «nueva» desde V.
¿Dije «reaplicar V»? Eso no tiene sentido. V es un commit, por lo tanto es un estado de mi contenido. No puedo aplicar un estado a otro estado; sólo puedo aplicarle diferencias a un estado para llegar a otro estado. Lo que Git hace es encontrar las diferencias de A a V (a esto llamémosle diff[A→V]) y eso se lo aplica a C para llegar a V.
¿Dije que sobre C queda V? Eso tampoco es cierto. V en realidad es A + diff[A→V]. Lo que en realidad quedaría es C + diff[A→V], que no es lo mismo. Le llamaremos V’. Es decir, es reaplicar el mismo parche que V le aplica a A pero partiendo de otro estado de código, de C. Entonces:
Originalmente:
V = A + diff[A→V]
Después del Rebase:
V’ = C + diff[A→V]
Rebase puede reaplicar los cambios sobre la misma base original, es decir, no mover la rama de lugar. Esta reaplicación se puede hacer de manera interactiva para editar los commits durante el proceso. Esto permite limpiar una rama antes de someterla a consideración para su integración por el mantenedor del proyecto.
Conclusiones: puntos de similitud y diferencia
Tras hacer un Rebase de una rama sobre otra, la rama que se mueva contendrá también la rama original, por lo que es parecido al resultado de Git Merge: una mezcla del contenido de las dos ramas (en nuestro ejemplo, de C y V). Esta es una similitud con Merge, sin embargo, con Rebase se manipuló una sola rama.
De hecho, después de un Rebase, para integrar la nueva rama a la rama original, se necesita hacer el Merge. Si la rama master ya no tiene commits nuevos, basta con un Merge de avance rápido.
Y finalmente lo que en su momento contesté: si mezclar mi rama con upstream causará un conflicto y al pedir el pull-request el mantenedor deberá resolver los conflictos. Por el contrario, si antes del pull-request hago un Rebase interactivo, seré yo quien resuelva los conflictos y así facilito el Merge que realice el mantenedor. No es una cuestión de usar Rebase o Merge, sino de agregar un Rebase interactivo o no, antes del Merge. El Merge nunca queda fuera.
Dicho de otra manera: Rebase y Merge se usan en conjunto. Cuando se usa Rebase, el Merge necesario suele ser un avance rápido (fast-forward).
Entonces:
- Si necesitas limpiar tu historial antes de publicarlo, Merge no es opción, sólo Rebase (en modo interactivo) o Commit en modo amend. Si necesitas actualizar una rama para que se construya sobre la base de código más reciente, Merge no es opción.
- Si necesitas incorporar tu rama a otra o mezclar dos ramas, Rebase no es opción, sólo Merge: quien hace la mezcla es Merge, aún después de que el historial de una rama haya sido limpiado por Rebase y sólo se necesite de un Merge de tipo avance rápido.