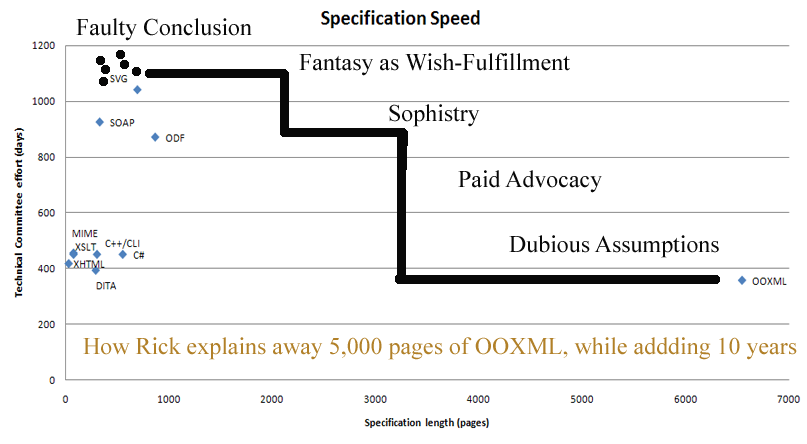
Microsoft Office OpenXML es un formato para diversos tipos de documentos propuesto por Microsoft que cuenta con las siguientes ventajas (puede ahondar en cada una haciendo clic en cada línea):
- Es un estándar internacional chueco.
- Está lleno de defectos.
- No es de libre implementación.
- … y muchos otros beneficios.
Me da tristeza saber que mi propio país colaboró con esta aberración. Esto está explicado también en Groklaw, pero cita al Excelsior con un link que ya no existe (y que por eso puse el link a El Imparcial). Transcribo, debido a que es un tema acompañado por otros temas en la misma página:
Gates habla
Nada más para que se dé idea de la magnitud de la presión que se está ejerciendo en torno al voto de México en el seno de la Organización Internacional de Estandarización respecto del futuro de Open XML.
Trascendió que el mismo Bill Gates se comunicó con Felipe Calderón para influir en la postura que se hará pública el próximo lunes en Ginebra.
Aquí la comisión gubernamental está un tanto incómoda por la posición de algunos representantes de la UNAM, en especial la de Alejandro Pisanty, ex director general de Servicios de Cómputo Académico. Se trata de un respetado investigador que critica fuertemente el estándar que impulsa Microsoft. Su posición es estrictamente teórica a favor del software libre.
Actualización: Gracias al blog de Miriam Ruiz, me entero de que aún hay esperanza. Ya que su entrada está en inglés, y y lo expresó de forma insuperable, traduzco literalmente:
Después de la aprobación de OOXML como un estándar por ISO, parece que hay dos meses para apelar la decisión. La Comisión Europea, la más alta autoridad antimonopolio, investigará si OOXML, como se le conoce al formato, es «suficientemente interoperable con productos de la competencia», así como si hubo irregularidades o intentos de influenciar el debate o la votación. Si los cuerpos nacionales de ISO aportan evidencia de que Microsoft intentó influenciar los votos para asegurar la aceptación de OOXML, fortalecería el caso antimonopolio de la Comisión. De acuerdo con Thomas Vinje, cónsul legal del Comité Europeo pro Sistemas Interoperables (ECIS), «incluso si los votos fueron ganados legítimamente ganados, que lo dudo, OOXML no es un estándar abierto puesto que no está completamente implementado en plataformas de competidores, y su forma futura está sujeta puramente al control de Microsoft. Otorgar el estatus de ISO a OOXML no comienza a resolver los cuestionamientos legales de la competencia que la Comisión está indagando.» Esperemos que la Unión Europea investigue y clarifique todo esto.
“Una apelación tendría que ser resuelta antes de la publicación de un documento como un estándar Internacional», dijo Roger Frost, vocero de ISO. En otras palabras, si se emite una apelación, es viable que la publicación final de OOXML como estándar se demore. Esperemos que el proceso de apelación de ISO, si se sigue, sea menos irregular que el de aprobación. Tal vez pueda recuperar mi confianza en ISO. Veremos qué pasa.